최근 우리 회사는 개발팀을 위해 안전한 **Private AI(AWS Bedrock 기반 Claude)**를 전격 도입했다. 비싼 인프라가 구축된 만큼, 리더십이 명확한 **ROI(퍼포먼스)**를 요구하는 것은 기업 입장에서 지극히 자연스러운 수순이다.
단순히 "코딩 속도가 빨라졌습니다"라는 주관적인 어필이나, 억지로 짜낸 일회성 유즈케이스 발굴로는 한계가 명확하다. AI의 파편화된 지식을 하나의 시스템으로 통제하고, 명확한 '판단 기준'을 통해 진짜 생산성을 측정하는 방법을 팀 단위에서 고민해야 할 시점이라고 생각한다.
토스(Toss) 프론트엔드 팀의 AI 도입 사례와 우리의 현실을 비교하며, 도구 중심주의에서 비롯된 FOMO에서 벗어나 팀 단위에서 LLM을 활용한 파이프라인을 구축하는 아이디어를 공유하고자 한다.
1. 대화만 해도 쌓이는 사내 지식과 죽은 문서 해결 (Passive RAG)
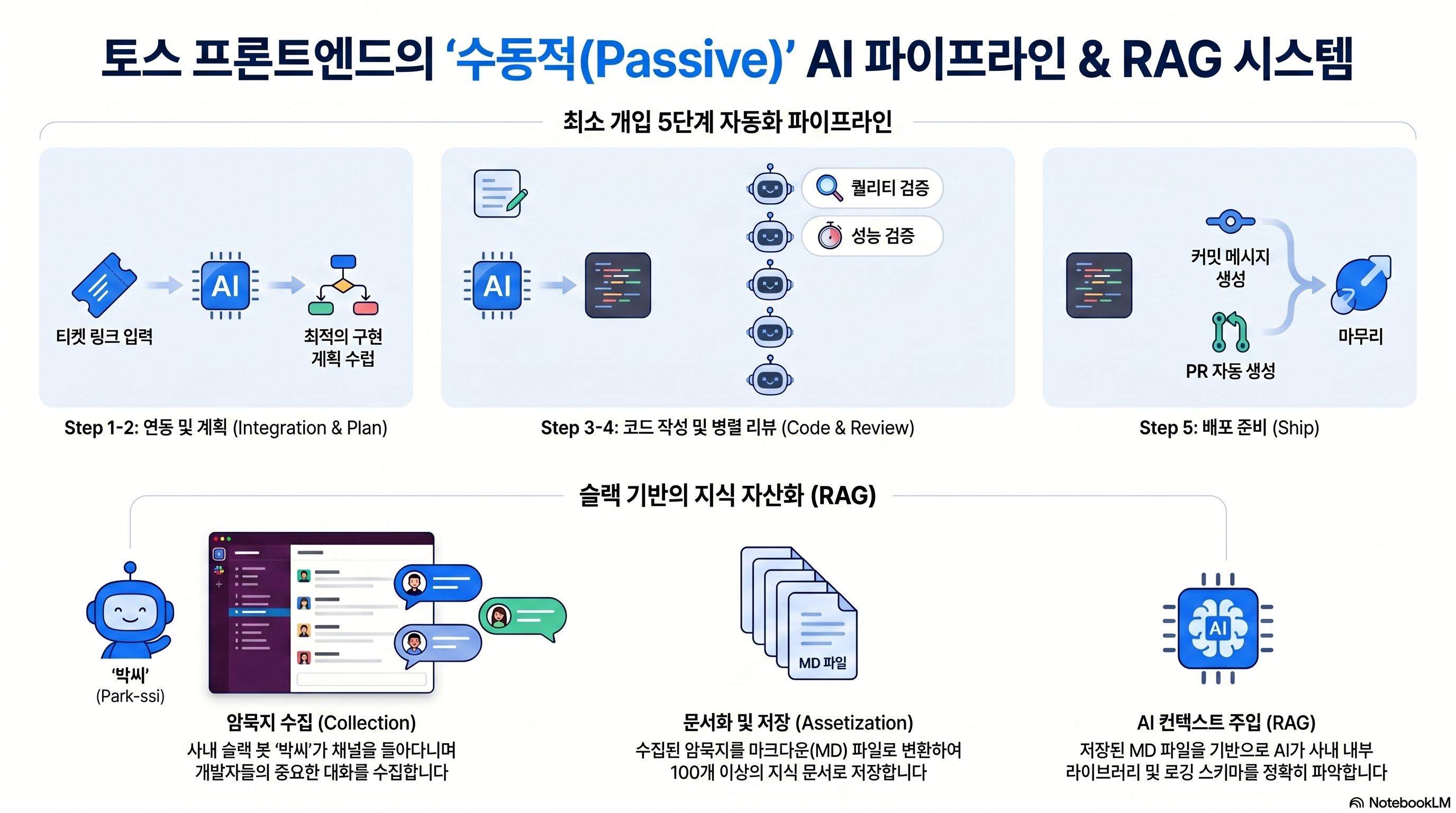
TOSS의 문제 제기와 도입 방법
- 문제 제기: AI가 제대로 된 코드를 짜려면 사내의 Context에 대한 Working Memory가 필요하다. 하지만 팀원들에게 "AI 학습용 문서를 주기적으로 작성하라"고 강제하면 결국 아무도 쓰지 않게 되고 지식은 업데이트되지 않는다.
- 도입 방법: 토스는 사내 메신저를 돌아다니며 개발자들의 대화 속에서 유용한 암묵지나 디버깅 내역을 감지하면 Markdown 파일로 자동 문서화하는 봇(AKA. 박씨)를 운영한다. 메신저 내의 팀원들의 인사이트가 100개 이상의 문서로 자동 저장되어 AI의 배경 지식으로 즉각 연동되는 Passive RAG 구조를 만들었다.
우리 팀의 문제와 도입 방법
- 문제 제기: 우리 팀 역시 AI에게 사내 컨텍스트를 주입해야 하지만, 메인 위키인 Confluence에는 방치된 '죽은 문서(Dead Docs)'가 쌓일 수 밖에 없다. 이 상태로 RAG를 연동하면 AI가 잘못된 레거시 정보를 참고할 위험이 매우 높다.
- 도입 방법: 문서 정리 역시 팀원의 개입 없이 시스템이 백그라운드에서 유효기간이 지난 지식을 가중치에서 제거하도록 만들어야 한다. 업데이트가 멈춘 Confluence 문서는 백그라운드 스크립트가 스스로 식별해 검색에서 원천 배제하거나, 최신 날짜의 문서에 높은 검색 가중치를 부여해 정보의 신선도를 기계적으로 유지한다. 이 시스템과 메신저 자동 수집 봇을 결합하면, 오래된 레거시는 걸러지고 최신 지식은 알아서 쌓이는 지속 가능한 컨텍스트 엔지니어링(Context Engineering) 환경이 완성된다.
💡 Action Item
- 방치된 문서의 자동 아카이빙 Easy
마지막 업데이트나 조회일이 일정 기간(예: 6개월) 지난 Confluence 문서를 백그라운드 스크립트가 식별하여 '[Archive]' 태그를 붙이고 검색 대상에서 원천 배제한다. - RAG 검색 가중치 조정 Easy
문서 검색 시 단순 키워드가 아닌 '최근 수정일' 메타데이터에 높은 가중치를 부여하여, 충돌하는 지식이 있을 경우 항상 최신 날짜의 정보가 AI의 답변에 반영되도록 신선도를 기계적으로 유지한다. - 메신저 봇 연동을 통한 지식 자동 수집 Medium
사내 메신저(Slack 등) 개발 채널에서 오가는 유용한 디버깅 스레드나 논의를 AI가 감지해 기계가 읽기 좋은 Markdown 파일로 자동 저장하도록 구성한다.
2. 프롬프트가 필요 없는 무개입형 파이프라인 구축
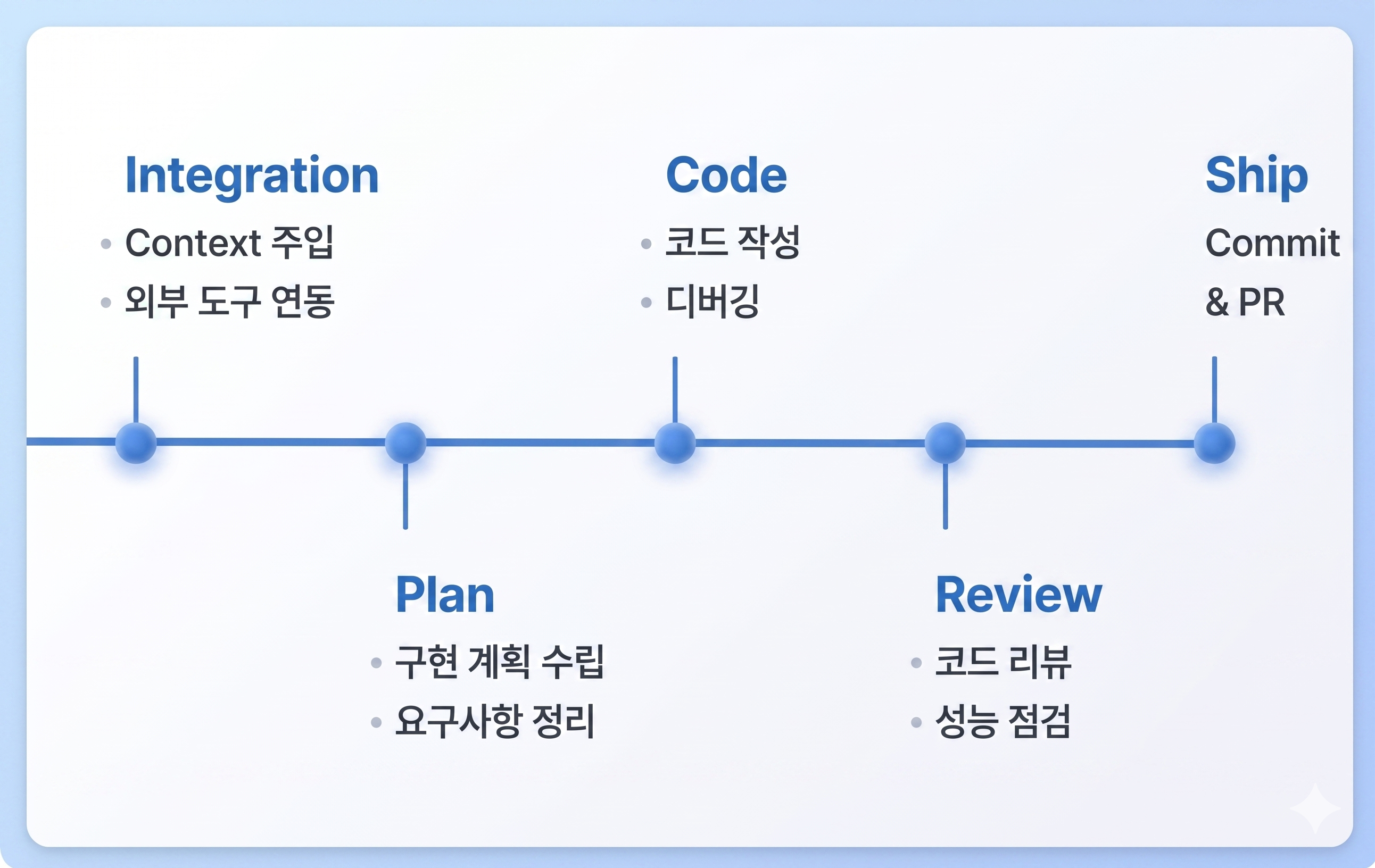
TOSS의 문제 제기와 도입 방법
- 문제 제기: 토스 프론트엔드 팀 역시 개인과 오픈소스에서 쏟아지는 AI 스킬들 속에서 혼란을 겪었다. 특히 '아는 사람만 잘 쓰는' **AI 활용 역량의 빈부격차(Distribution)**와, 검증되지 않은 스킬들이 파편화되어 서로 충돌하는 현상이 가장 큰 문제였다.
- 도입 방법: 이를 해결하기 위해 에이전트가 코드를 생산하고 검증하는 5단계 파이프라인(
Integration->Plan->Code->Review->Ship)을 구축했다. 구성원이 복잡한 프롬프트를 고민할 필요 없이 티켓 링크만 넣으면 알아서 실행되는 통합 스킬(tap-use-integration)을 만들었고, **백그라운드 훅(Hook)**을 통해 클로드를 실행할 때마다 최신 사내 표준 스킬로 자동 업데이트되도록 환경을 통제했다.
우리 팀의 문제와 도입 방법
- 문제 제기: 현재 우리 팀도 개개인의 AI 사용법과 역량이 모두 달라서 파편화가 일어나고 있다. 일회성 작업 위주로 AI를 사용하다 보니 히스토리가 남지 않고, 사내의 좋은 Usecase를 전파하기가 어렵다.
- 도입 방법: 우리도 억지로 프롬프트 엔지니어링을 강제하는 대신, 준비된 라이브러리 함수를 호출하듯 시스템적인 통제력을 갖춘 수동적(Passive) 파이프라인을 구축해야 한다. 팀원들이 JIRA 티켓
URL만 던지면 AI가 알아서 문서 검색, 계획, 코딩을 연달아 수행하도록 통합 라우팅 스킬을 세팅한다. 나아가 발견된 좋은 활용법은Hook을 통해 팀원들의 로컬 환경에 충돌 없이 조용히 스며들게 만들어, 개인의 역량에 의존하지 않고 시스템 레벨에서 AI 활용의 상향 평준화가 필요하다.
💡 Action Item
- 환경 설정 자동화(Hook) Easy
사내 베스트 프랙티스가 발견되면 이를 표준 스킬로 등록하고, 팀원들이 실행할 때마다 충돌 없이 조용히 최신 환경으로 업데이트되도록 'Auto-update' 훅을 구축한다. - 통합 라우팅 스킬 세팅 Hard
복잡한 프롬프트를 작성할 필요 없이, 입력창에 JIRA 혹은 Linear 이슈 티켓 URL만 던지면 AI가 문서 검색, 계획 수립, 코딩을 연달아 수행하도록 스킬을 통합한다. - 역할의 분리와 병렬 검증 Hard
코드를 짜는 에이전트와 리뷰하는 에이전트를 분리(최대 5개 병렬 리뷰)하여 사람의 검증 병목과 피로도를 시스템적으로 낮춘다.
3. 속도가 아닌 '진짜 생산성' 증명하기 (Focus on Impact)

TOSS의 문제 제기와 도입 방법
- 문제 제기: 토스는 AI 도입 후 한 달 만에 PR 수가 1.8배 증가하며 생산성이 오른 줄 알았으나, 데이터를 뜯어보니 버그를 고치는
Fix PR비율도 함께 폭증하는 '생산성의 절망편'을 겪었다. 코딩 속도만 빨라지는 것은 결국 "빠르게 만들고 빠르게 고치고 있는 것"에 불과했다. - 도입 방법: 도구 자체에 쫓기지 않고 본질적인 '생산성'을 명확히 정의하고 측정하기 시작했다. 코딩 속도 대신, 제품이 안정적으로 운영되고 있는지 확인하는 '제품 퀄리티(버그 지수)'와, 파이프라인의 자율화 수준(L0~L5)을 평가해 아이디어가 프로덕션에 얼마나 빨리 도달하는지 확인하는 '이터레이션 속도(DX Index)'를 분리하여 객관적으로 측정했다.
우리 팀의 문제와 도입 방법
- 문제 제기: 전사적인 Private AI 도입 앞에서 우리 역시 명확한 측정 기준이 없다면 "코딩 속도가 빨라졌습니다" 식의 주관적 어필에 그칠 위험이 크다. AI라는 특이점이 요구하는 생존 방법은 결국 실무적인 '생산' 속도가 아니라, '결과물에 대한 명확한 판단 기준'을 세우는 데 있다.
- 도입 방법: 팀 전체의 실질적 성과를 객관적으로 증명할 두 가지 핵심 지표를 확립하고 추적한다.
💡 Action Item
| 측정 지표 | 측정 산식 및 기준 | 측정 목표 |
|---|---|---|
| 제품 퀄리티 (버그 지수) Medium | Fix PR 비율 + Revert PR 추이 + 실제 롤백률 합산 | AI로 개발 속도를 획기적으로 높이면서도, 우리 제품의 건강도(안정성)를 완벽하게 유지하고 있음을 객관적으로 증명한다. |
| 이터레이션 속도 (DX Index) Medium | 파이프라인 자율화 수준 평가 (L0: 완전 수동 ~ L5: 의도만 던지면 완전 자율화) | 수동 작업(리뷰, 환경 세팅)을 AI로 자동화하여, 비즈니스 아이디어가 프로덕션에 도달하는 리드 타임을 실질적으로 단축했음을 증명한다. |
① 제품 퀄리티 (버그 지수) 자동 수집 개발자에게 새로운 입력 스트레스를 주지 않고, 시스템이 기계적으로 퀄리티를 추적하도록 세팅한다.
- [Step 1] PR 단위 자동 파싱 Easy
PR 생성 시 연동된 Jira 티켓의 이슈 타입을 CI/CD 스크립트가 백그라운드에서 읽어온다. 전체 작업 중 버그를 고치는Fix PR비율이 얼마나 되는지 기계적으로 집계한다. - [Step 2] 리버트 및 롤백 추적 Easy
배포 후 코드를 되돌리는Revert PR의 빈도와 인프라 레벨의 실제 롤백률을 시스템이 감지하여 버그 지수에 합산한다. - [Step 0] Jira 이슈 타입 표준화 Medium
팀원들이 티켓을 생성할 때Task,Bug,Enhancement등의 이슈 타입을 명확히 선택하도록 지라 환경과 템플릿을 우선 세팅한다.
② 이터레이션 속도 (DX Index) 측정 완벽한 샌드박스 인프라가 없음을 인지하고, 현재 환경에 맞는 안전한 수동 병목 구간부터 리드 타임을 줄여나간다.
- [Step 1] 베이스라인 지표 수집 Easy
무리하게 샌드박스를 구축하는 대신, 현재 파이프라인의 출구 지표인 배포 리드 타임, 배포 성공률, 배포 빈도를 수집하여 베이스라인으로 삼는다. - [Step 0] 파이프라인 진단 Medium
코드 작성부터 프로덕션 배포까지의 전체 과정(작성 -> 리뷰 -> QA -> 배포)을 분해하고, 현재 우리 팀의 자율화 수준(예: L1.5)을 객관적으로 진단한다. - [Step 2] 안전한 구간부터 L2(AI Assisted) 도입 Medium
시스템 인프라 변경 없이 즉시 도입 가능한 병목 구간(예: 리뷰 대기 시간을 줄이기 위한 AI PR 자동 요약 및 컨벤션 검사 등)에만 제한적으로 AI를 투입하고, 배포 리드 타임의 증감을 비교해 생산성을 증명한다.
마무리하며
기술 발전 속도와 AI가 생성하는 코드의 퀄리티는 지속적으로 상승하겠지만, AI는 결국 효율을 높이는 도구에 불과하다. 개인이 이 생산성의 우상향 그래프에 병목이 되지 않기 위해서는 팀 단위의 파이프라인을 구축하고, 동시에 명확한 지표를 통해 AI 활용의 생산성을 증명하는 방법을 계속해서 리서치 해야한다.